仮想通貨をターゲットにした機械学習には、過去のデータが必要不可欠です。
過去に自前でビットコインをクロールするプログラムについて説明しましたが、実は過去の取引データはKaggleというサイトで配布されています。
この記事ではKaggleから過去データを取得し、Python notebookでデータを可視化する方法についてご紹介します。
関連:bitFlyerのAPIでティッカーを自動取得する【仮想通貨】
データのダウンロード
ビットコインの過去データはKaggleの以下のサイトからダウンロードすることができます。
https://www.kaggle.com/mczielinski/bitcoin-historical-data
この記事を作成した時点では、2018/11/11までの取引データが配布されています。

赤枠で示した「Download」をクリックすることで、データをダウンロードできます。
ダウンロードにはKaggleのアカウントが必要で、もし持っていないのであれば以下のような登録画面が表示されます。
Googleアカウントなどで認証することで、アカウントが作成されデータが取得できるようになります。
登録画面は投稿現在で英語画面しかありませんが、基本的に「I agree」にチェックを入れておけば問題ありません。
以下のファイルがダウンロードされていれば成功です。

zipファイルなので、ダブルクリックすることで展開しましょう。
中に入っているcsvファイルはとても大きいため、エクセルなどで開かないようにしましょう!
パソコンが数分フリーズする可能性があります。
中身を見てみる
では展開したフォルダを見てみましょう。
フォルダには以下の二つのファイルが入っています。
- bitstampUSD_1-min_data_2012-01-01_to_2018-11-11.csv
- coinbaseUSD_1-min_data_2014-12-01_to_2018-11-11.csv
ここで、to_2018-11-11の部分はダウンロードした時期によって最新のものに変わっているかと思います。bitstamp、coinbaseはそれぞれ取引所の名前ですね。
またファイル名からもわかる通り、ビットコインの価格はUSDで表示されていることに注意してください。
(ダウンロードした時期によってはJPYがあるかもしれません。)
日本円ではないので、そのまま日本円での運用に反映させるには一手間必要になりますが、全体の傾向をつかむためには十分すぎるデータでしょう。
さて、データの中身は実は先ほどのKaggleのサイトで確認することができます。
再度以下のサイトにアクセスし下の方にスクロールすると、画像のような表が見れるはずです。
https://www.kaggle.com/mczielinski/bitcoin-historical-data
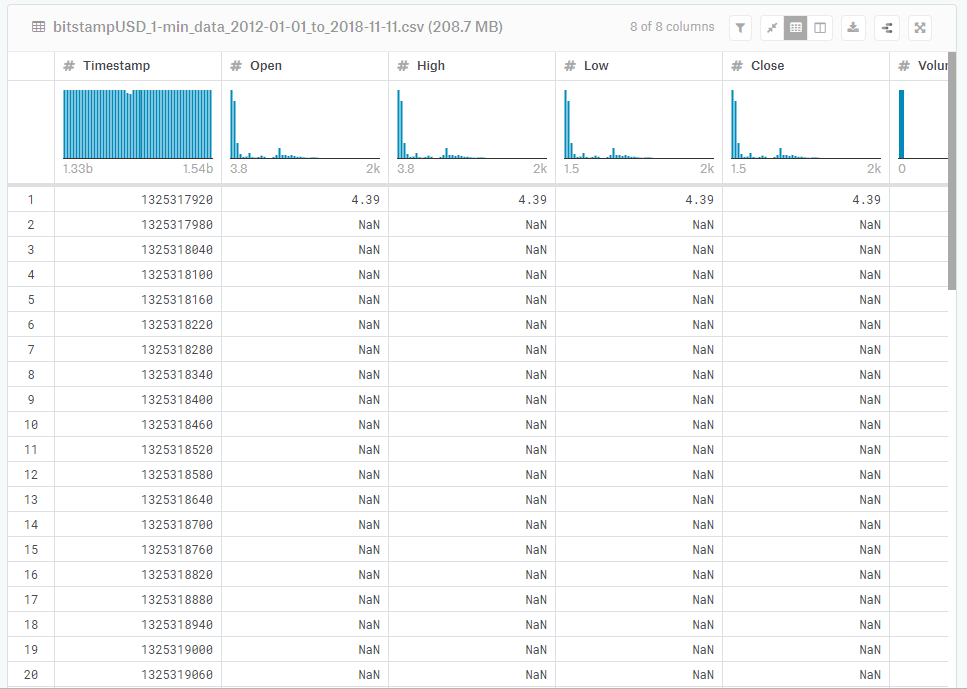
これはいまダウンロードしたcsvファイルの中身になります。
右側が見切れていますが、左から順番に
- Timestamp:
- Open:
- High:
- Low:
- Close:
- Volume_(BTC):
- Volume_(Currency):
- Weighted_Price:
の列となっています。
見ての通り「NaN」というデータが非常に多くなっています。
NaNはNot a Numberの省略で、いわゆる欠損値といわれるものです。
つまり、その時刻のデータは取得できていないということになります。
データ分析の観点から、欠損値を削除することは好ましくありませんが、今回はデータの傾向を見たいだけなので欠損値を排除したデータを作ってみます。
以下のようなpythonコードによって、欠損値のないデータを得ることができます。
import csv
# bitstampのデータを整形する
with open('bitstampUSD_1-min_data_2012-01-01_to_2018-11-11.csv') as f:
reader = csv.reader(f)
header = next(reader)
# 欠損していないデータだけのリスト
data = [list(map(float, row)) for row in reader if row[1]!='NaN'] # floatにしておく
こうすることで、data変数に欠損していないデータを代入することができます。
dataの中身は以下のようになっています。
>>> data[:10] [[1325317920.0, 4.39, 4.39, 4.39, 4.39, 0.45558087, 2.0000000193, 4.39], [1325346600.0, 4.39, 4.39, 4.39, 4.39, 48.0, 210.72, 4.39], [1325350740.0, 4.5, 4.57, 4.5, 4.57, 37.86229723, 171.38033753, 4.5264114983], [1325350800.0, 4.58, 4.58, 4.58, 4.58, 9.0, 41.22, 4.58], [1325391360.0, 4.58, 4.58, 4.58, 4.58, 1.502, 6.87916, 4.58], [1325431680.0, 4.84, 4.84, 4.84, 4.84, 10.0, 48.4, 4.84], [1325457900.0, 5.0, 5.0, 5.0, 5.0, 10.1, 50.5, 5.0], [1325534640.0, 5.0, 5.0, 5.0, 5.0, 19.048, 95.24, 5.0], [1325591100.0, 5.32, 5.32, 5.32, 5.32, 2.41917293, 12.869999988, 5.32], [1325600520.0, 5.14, 5.14, 5.14, 5.14, 0.68, 3.4952, 5.14]]
欠損していないデータだけが取得できていますね。
一番左の列はタイムスタンプですが、このままでは具体的な時刻がわからないので、以下のようにして時刻に変換しておきましょう。
data = [[str(datetime.fromtimestamp(row[0]))]+row[1:] for row in data]
最初の30時刻分を表示してみると、以下のようになります。
>>> data[:30] ['2011-12-31 07:52:00', 4.39, 4.39, 4.39, 4.39, 0.45558087, 2.0000000193, 4.39] ['2011-12-31 15:50:00', 4.39, 4.39, 4.39, 4.39, 48.0, 210.72, 4.39] ['2011-12-31 16:59:00', 4.5, 4.57, 4.5, 4.57, 37.86229723, 171.38033753, 4.5264114983] ['2011-12-31 17:00:00', 4.58, 4.58, 4.58, 4.58, 9.0, 41.22, 4.58] ['2012-01-01 04:16:00', 4.58, 4.58, 4.58, 4.58, 1.502, 6.87916, 4.58] ['2012-01-01 15:28:00', 4.84, 4.84, 4.84, 4.84, 10.0, 48.4, 4.84] ['2012-01-01 22:45:00', 5.0, 5.0, 5.0, 5.0, 10.1, 50.5, 5.0] ['2012-01-02 20:04:00', 5.0, 5.0, 5.0, 5.0, 19.048, 95.24, 5.0] ['2012-01-03 11:45:00', 5.32, 5.32, 5.32, 5.32, 2.41917293, 12.869999988, 5.32] ['2012-01-03 14:22:00', 5.14, 5.14, 5.14, 5.14, 0.68, 3.4952, 5.14] ['2012-01-03 14:54:00', 5.26, 5.26, 5.26, 5.26, 29.31939163, 154.21999997, 5.26] ['2012-01-03 15:32:00', 5.29, 5.29, 5.29, 5.29, 29.30245747, 155.01000002, 5.29] ['2012-01-03 17:10:00', 5.29, 5.29, 5.29, 5.29, 11.28544423, 59.699999977, 5.29] ['2012-01-03 17:14:00', 5.14, 5.14, 5.14, 5.14, 0.02, 0.1028, 5.14] ['2012-01-03 17:26:00', 5.29, 5.29, 5.29, 5.29, 11.0, 58.19, 5.29] ['2012-01-03 17:27:00', 5.29, 5.29, 5.29, 5.29, 4.01081466, 21.217209551, 5.29] ['2012-01-04 04:17:00', 4.93, 4.93, 4.93, 4.93, 2.32, 11.4376, 4.93] ['2012-01-04 05:05:00', 4.93, 4.93, 4.93, 4.93, 9.68, 47.7224, 4.93] ['2012-01-04 12:41:00', 5.19, 5.19, 5.19, 5.19, 2.6416185, 13.710000015, 5.19] ['2012-01-04 12:57:00', 5.19, 5.19, 5.19, 5.19, 8.72447013, 45.279999975, 5.19] ['2012-01-04 15:39:00', 5.19, 5.19, 5.19, 5.19, 16.34472603, 84.829128096, 5.19] ['2012-01-04 15:53:00', 5.32, 5.32, 5.32, 5.32, 0.18609023, 0.9900000236, 5.32] ['2012-01-04 15:54:00', 5.32, 5.32, 5.32, 5.32, 10.39473684, 55.299999989, 5.32] ['2012-01-04 16:00:00', 5.36, 5.37, 5.36, 5.37, 13.62942272, 73.060000006, 5.3604618117] ['2012-01-04 17:51:00', 5.37, 5.57, 5.37, 5.57, 43.31219578, 235.74706937, 5.4429720112] ['2012-01-05 01:40:00', 5.72, 5.72, 5.72, 5.72, 5.0, 28.6, 5.72] ['2012-01-05 03:52:00', 5.75, 5.75, 5.75, 5.75, 5.2, 29.9, 5.75] ['2012-01-05 07:19:00', 5.75, 5.79, 5.75, 5.79, 14.8, 85.5, 5.777027027] ['2012-01-05 08:58:00', 6.0, 6.0, 6.0, 6.0, 2.23666667, 13.42000002, 6.0] ['2012-01-05 09:03:00', 6.0, 6.0, 6.0, 6.0, 0.1684827, 1.0108962, 6.0]
…だいぶ歯抜けですね。
これはかなり古い時期のためにサーバーが安定していないなどの理由がありそうです。
ある程度時間がたった2013年ごろのデータは以下のようにかなり安定して数分おきにデータが取得できています。
>>> data[100000:100030] ['2013-05-14 05:13:00', 115.52, 115.52, 115.52, 115.52, 0.4, 46.208, 115.52] ['2013-05-14 05:14:00', 115.52, 115.94, 115.52, 115.94, 16.22604831, 1875.6897408, 115.59744584] ['2013-05-14 05:15:00', 115.94, 115.94, 115.94, 115.94, 0.56595169, 65.616438939, 115.94] ['2013-05-14 05:16:00', 115.94, 115.94, 115.94, 115.94, 0.4, 46.376, 115.94] ['2013-05-14 05:17:00', 115.94, 115.95, 115.94, 115.94, 1.4, 162.32277952, 115.94484251] ['2013-05-14 05:18:00', 115.95, 115.95, 115.95, 115.95, 0.4, 46.38, 115.95] ['2013-05-14 05:19:00', 115.94, 115.94, 115.94, 115.94, 0.4, 46.376, 115.94] ['2013-05-14 05:20:00', 115.94, 115.94, 115.94, 115.94, 0.4, 46.376, 115.94] ['2013-05-14 05:21:00', 115.94, 115.94, 115.54, 115.54, 6.628, 765.95912, 115.56414001] ['2013-05-14 05:22:00', 115.54, 115.54, 115.54, 115.54, 0.4, 46.216, 115.54] ['2013-05-14 05:23:00', 115.54, 115.54, 115.54, 115.54, 0.4, 46.216, 115.54] ['2013-05-14 05:24:00', 115.54, 115.54, 115.54, 115.54, 2.964, 342.46056, 115.54] ['2013-05-14 05:25:00', 115.53, 115.54, 115.53, 115.53, 0.9, 103.981, 115.53444444] ['2013-05-14 05:26:00', 115.53, 115.53, 115.53, 115.53, 4.4, 508.332, 115.53] ['2013-05-14 05:27:00', 115.53, 115.53, 115.53, 115.53, 2.4, 277.272, 115.53] ['2013-05-14 05:28:00', 115.53, 115.53, 115.53, 115.53, 2.947, 340.46691, 115.53] ['2013-05-14 05:29:00', 115.53, 115.53, 115.53, 115.53, 0.4, 46.212, 115.53] ['2013-05-14 05:30:00', 115.53, 115.53, 115.53, 115.53, 0.4, 46.212, 115.53] ['2013-05-14 05:31:00', 115.53, 115.53, 115.53, 115.53, 0.4, 46.212, 115.53] ['2013-05-14 05:32:00', 115.53, 115.53, 115.53, 115.53, 0.4, 46.212, 115.53] ['2013-05-14 05:33:00', 115.53, 115.53, 115.53, 115.53, 1.51468883, 174.99200053, 115.53] ['2013-05-14 05:34:00', 115.53, 115.53, 115.53, 115.53, 0.4, 46.212, 115.53] ['2013-05-14 05:35:00', 115.52, 115.53, 115.5, 115.53, 4.55, 525.586, 115.51340659] ['2013-05-14 05:36:00', 115.52, 115.52, 115.52, 115.52, 0.6, 69.312, 115.52] ['2013-05-14 05:37:00', 115.42, 116.15, 115.42, 115.44, 9.36049165, 1080.4087312, 115.42222049] ['2013-05-14 05:38:00', 116.15, 116.15, 116.15, 116.15, 0.4, 46.46, 116.15] ['2013-05-14 05:39:00', 116.14, 116.14, 116.14, 116.14, 0.4, 46.456, 116.14] ['2013-05-14 05:40:00', 116.13, 116.14, 116.13, 116.14, 2.21708283, 257.48799988, 116.13819583] ['2013-05-14 05:41:00', 116.09, 116.09, 116.09, 116.09, 0.4, 46.436, 116.09] ['2013-05-14 05:42:00', 116.09, 116.09, 116.09, 116.09, 0.46003962, 53.405999486, 116.09]
グラフにしてみよう
最後にhighとlowの値を使ってグラフを書いてみましょう。
# highとlowを抜き出す >>> highs = [row[2] for row in data] >>> lows = [row[3] for row in data] >>> import matplotlib.pyplot as plt >>> begin = 1500000 # 2017-01-26 12:38:00のデータから >>> end = -1 # 2018-11-10 23:59:00のデータ(最新)まで >>> plt.plot(range(begin,end),highs[begin:end]) >>> plt.plot(range(begin,end),lows[begin:end])
以上のコードを実行すると、以下のグラフが描画されます。
縦軸がドル、横軸が時間です。
潰れてしまっていますが、青がhigh、緑がlowとなっています。
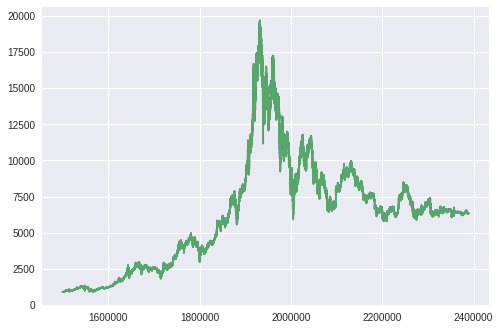
コメントに書いている通り2017/01/26から2018/11/10のデータなので、ビットコインの栄枯盛衰がばっちり表示されていますね。
また2018年12月現在の価格はさらに低くなっていますが、このデータではまだ反映されていません。
まとめ
今回はKaggleからビットコインのデータをダウンロードし、中身を確認したうえでグラフに表示してみました。
データ分析を始めるためにはまずデータを取得し、傾向を確認することが重要です。
今後はこのデータを使って機械学習によるデータ予測の方法などを分かりやすく紹介していきます!




